
Préparé par Bernard Polarski , Juin 2013
Voici comment extraire et formater en un document Word, un texte PDF downloadé de Gallica.bnf.fr.
Si votre PDF ne vient pas de Gallica, il se peut que cette méthode ne fonctionne pas, car Gallica scanne ses PDF
selon le format ALTO et garanti 99.985% de reconnaissance.
http://www.bnf.fr/fr/professionnels/num_conversion_texte/s.num_conversion_texte_ocr.html
La méthode que l'on presente ici remplace en efficacité et
rendu du texte la méthode plus classique qui consiste à importer le PDF dans un
OCR.
Il y a bien sur des fautes mais cette méthode donne un rendu du texte
supérieur à 99.9%.
2)
Perte d'une partie du formatage.
Le
redressement de cette perte est l'objet de ce tutorial. Les têtes de chapitres et autre
mises en pages spéciales
doivent être faites manuellement. En termes de temps, c'est relativement léger.
3)
Inversion de mots si la page PDF n'est pas plate. Le mot peut même se
perdre sur un autre ligne.
Cependant
c'est relativement rare. Un image PDF 'stable' ne produit aucune erreur
de texte.
4) Aucun support image.
En fait ce n'est pas grave, car
de toute façon on ne traite pas les images avec l'OCR mais toujours
avec gimp.
Pour la bataille du grand couronné de Nancy, toutes images ont été sorties avec pdftoimage.exe et chargées
dans gimp, pour traitement avant de les réintroduire dans le word.
Nous aurons besoin du freeware ‘xpdf’ que l’on peut trouver ici :
Comme je travaille sous windows Seven home édition, j'utilise la version 32 bits. Adaptez selon votre version de Windows.

Ces utilitaires sont petits et très efficaces.

On les extrait dans un directory quelconque qui servira de 'repository' pour venir chercher le binaire
dont on aura besoin, ou bien vous mettez ce directory dans votre variable d'environnement %PATH%.
Maintenant
j’ai besoin d’un PDF. Je vais en prendre un difficile car qui peut le
plus peut
le moins.
Mon choix se porte sur « Souvenirs d'un aveugle, voyage autour du monde »
par Jacques Arago, H. Lebrun (Paris) Date d'édition : 1868
http://gallica.bnf.fr/ark:/12148/bpt6k6526526s.r=.langEN
Soit le document PDF suivant en deux colonnes que je souhaite transformer
en un document Word (étape intermédiaire, avant mon epub, où je ferais des corrections):
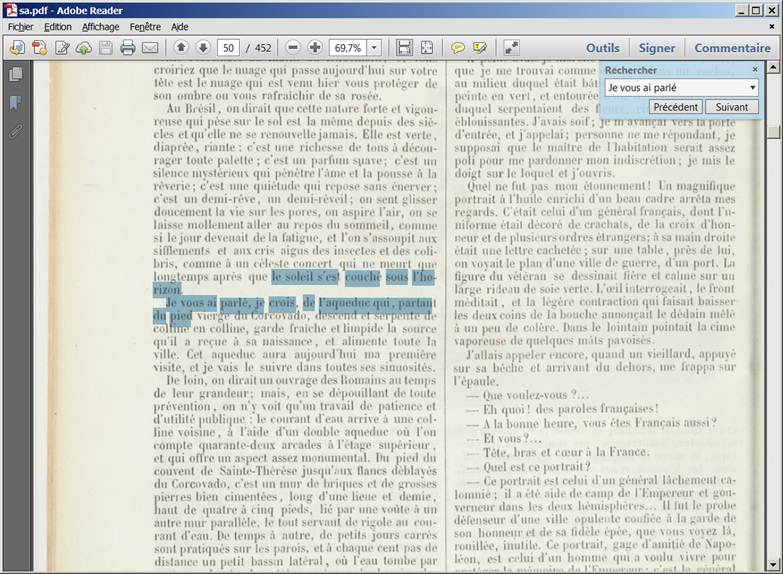


C’est le paramètre –raw qui redresse les deux colonnes en une colonne continue.
Les autres paramètres sont :
· -f 50 : Extraire à partir de la page 50 (ignorez pour faire tout le livre )
· -l 52 : Extraire jusqu’à la page 52 (ignorez pour faire tout le livre )
· -layout : en fait pas vraiment nécessaire, mais des fois je note un léger mieux dans le formatage, aussi je l’inclus toujours.
· -eol dos : end of line marker du format Dos (\n\c) par opposition au format Unix (\n)
· -nopgbrk : pas de saut de pages car ils sont plus un problème qu’autre chose et puis les sauts de pages sont inutiles dans un ePub.
Les seuls paramètres vraiment importants sont –raw et -nopgbrk
rajoutez ceci : -enc UTF-8 comme paramètre
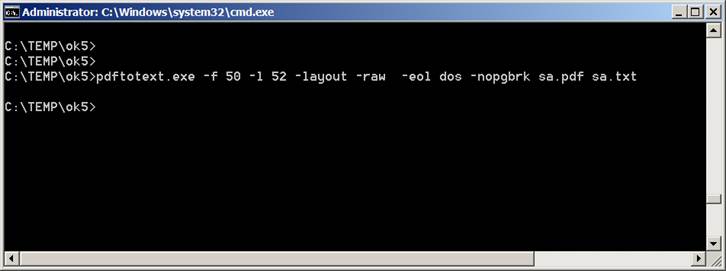
pdftotext.exe -raw -layout -enc UTF-8 fichier.pdf fichier.txt
Voici un extrait du ‘sa.txt’ produit:
«
; c'est une quiétude qui repose sans énerver;
c'est un demi-rêve, un demi-réveil; on sent glisser
doucement la vie sur les pores, on aspire l'air, on se
laisse mollement aller au repos du sommeil, comme
si le jour devenait dela fatigue, et l'on s'assoupit aux
sifflements et aux cris aigus des insectes et des coli-
bris, comme à un céleste concert qui ne meurt que
longtemps après que le soleil s'est couché sous l'ho-
rizon.
Je vous ai parlé, je crois, de l'aqueduc qui, partant
du pied vierge du Corcovado, descend et serpente de
colline en colline, garde fraiche et limpide la source
qu'il a reçue à sa naissance, et alimente toute la
ville. Cet aqueduc aura aujourd'hui ma première
visite, et je vais le suivre dans toutes ses sinuosités.
De loin, on dirait un ouvrage des Romains au temps
de leur grandeur; mais, en se dépouillant de toute
prévention, on n'y voit qu'un travail de patience et
d'utilité publique
«
J'ai mis en gras, une section du texte que je voudrais suivre, à travers ce tutorial.
Maintenant nous voudrions bien que notre
texte soit au moins formaté en paragraphe.
Je ne recherche pas la perfection mais simplement que le maximum de
travail soit fait.
Pour ce faire je vais utiliser au
maximum les possibilités de Word et un minimum de « regular
expressions. »
Voice le texte tel qu’il apparait dans Word, une fois importé. Je fais apparaitre les paragraphes :
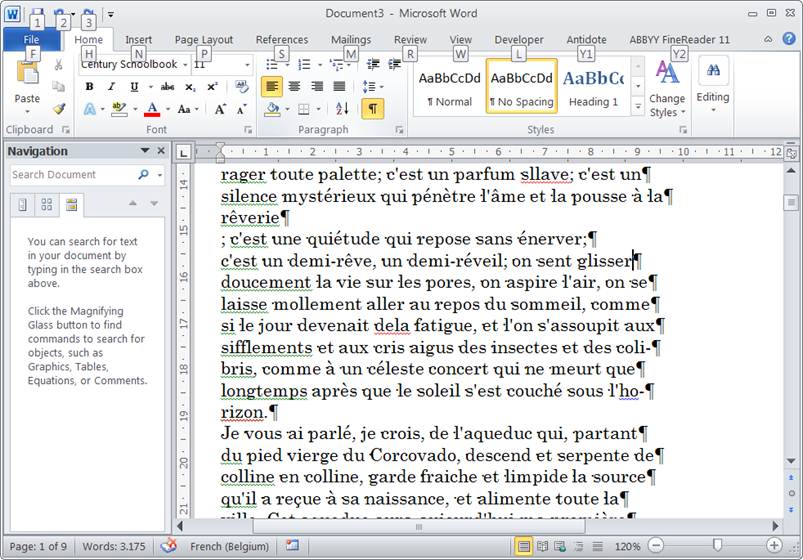
On voit bien que la plupart des marqueurs de fin de ligne ne sont pas dû.
C’est l’effet 'double colonnes' du texte original qui a fait des petites lignes.
On
ne voudrait garder que les marqueurs fins de lignes ![]() qui
terminent un
point
qui
terminent un
point
tandis que la ligne suivante commence par une majuscule.
Dans notre cas on devrait avoir :
«
… le soleil s'est couché sous l'horizon.
Je vous ai parlé, je crois, de l'aqueduc qui, partant du pied …
«
Un souci supplémentaire se pose. le ‘end
of paragraph ![]() se
note ‘^p’
mais n’est pas supporté
se
note ‘^p’
mais n’est pas supporté
quand on utilise les ‘regular expression dans word.
Aussi je commence donc par remplacer
tous les ![]() par
un string
XXP dont je suis sûr qu’il n’existe pas dans le texte original.
par
un string
XXP dont je suis sûr qu’il n’existe pas dans le texte original.
A
la fin je réintroduirais les ![]() par
une
opération inverse.
par
une
opération inverse.
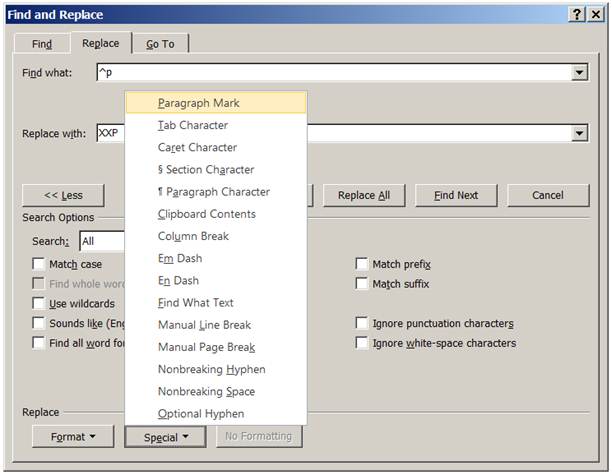
Notre texte ressemble à ceci :
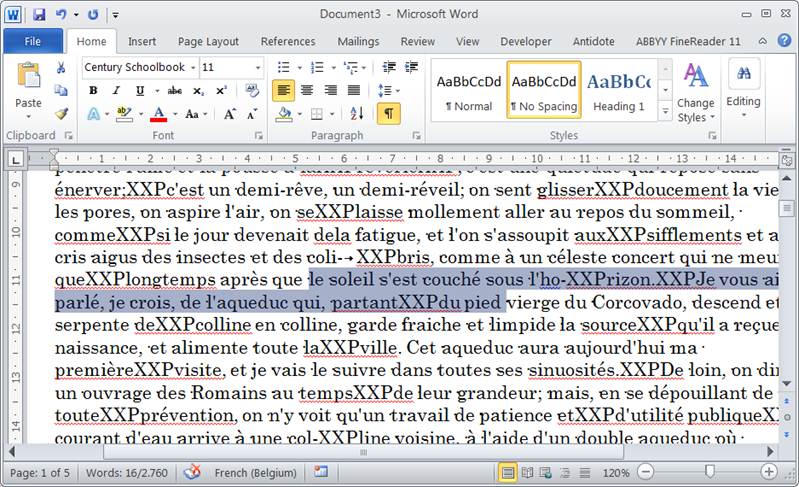
Je vais maintenant préserver tous les points suivit d’un XXP suivit d’une majuscule.
Car ils représentent la fin d'un paragraphe suivit d’un nouveau paragraphe.
Quant à
tous les autres marqueurs fin de paragraphe ![]() ,
on
va les
supprimer.
,
on
va les
supprimer.
Notez
que j’ai coché « Use wildcards » qui est ce qui tient
de ‘regular
expression’ en Word.
Nous introduisons notre expression régulière:
.XXX([A-Z])
et remplace par
.XXY\1
Pour la forme cette regular expression se traduit en bon français comme ceci :
Pour tout point, suivit de la chaine XXP suivit d’une majuscule,
remets le point, suivit de la chaîne XXY et remets la majuscule que tu as capturé.
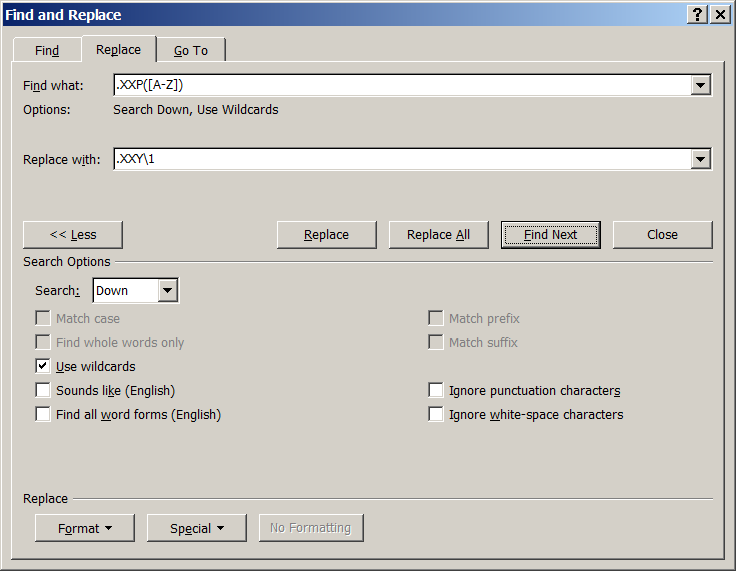
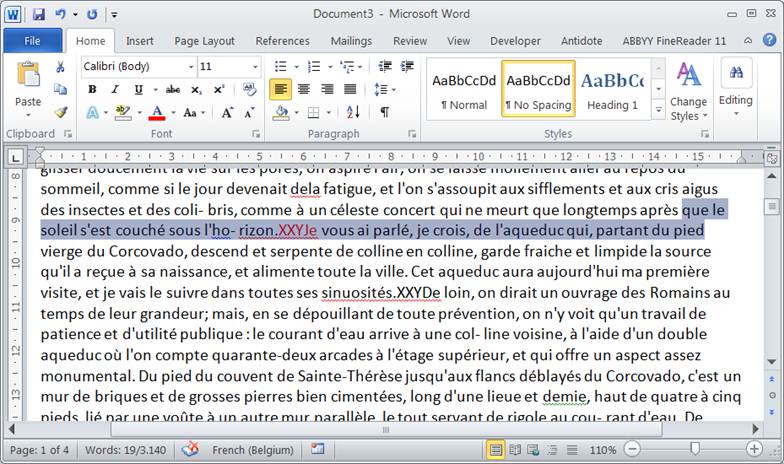
Un de nos XXP devient XXY notez la ligne :
«
qui ne meurt queXXPlongtemps après que le soleil s'est couché sous l'ho-XXPrizon.XXYJe vous ai parlé, je crois…
«
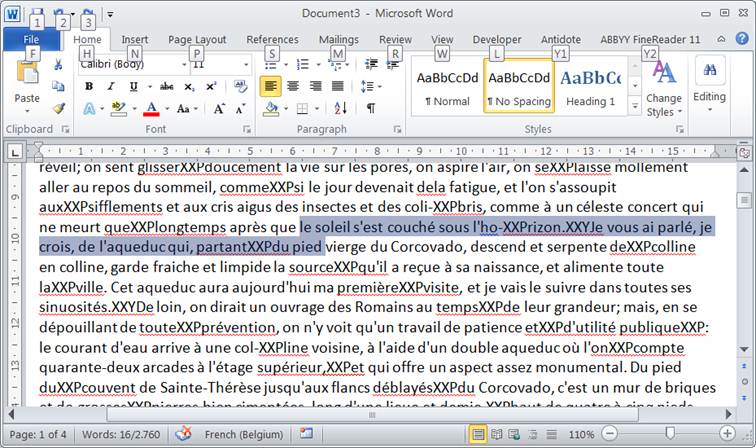
Si
vous n’avez pas coché ‘use wildcard’ il ne se passe rien. Vérifiez bien
qu’il y
a des XXY.
Maintenant
que j’ai identifié tous les vrais paragraphes, je supprime tous les XXP
restant
et les remplace par un espace :
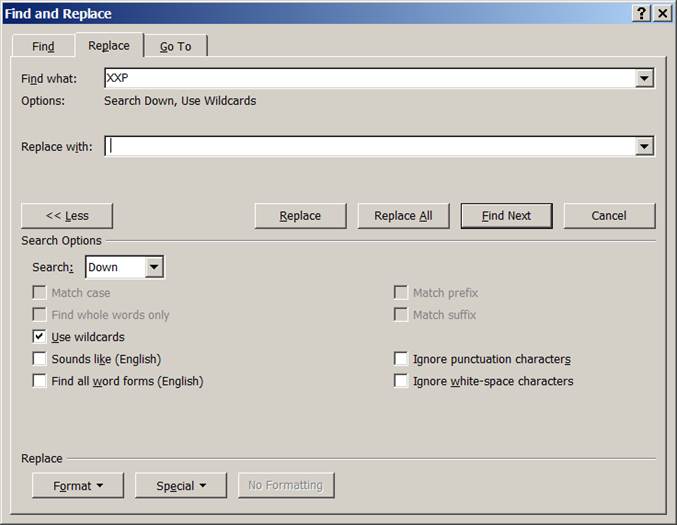
Mon texte ressemble à ceci :
Une seule longue chaîne de texte ou l’on note des XXY.
Je
vais remplacer tous les XXY par un ![]() et
ma nouvelle
ligne je la fait commencer par une tabulation :
et
ma nouvelle
ligne je la fait commencer par une tabulation :
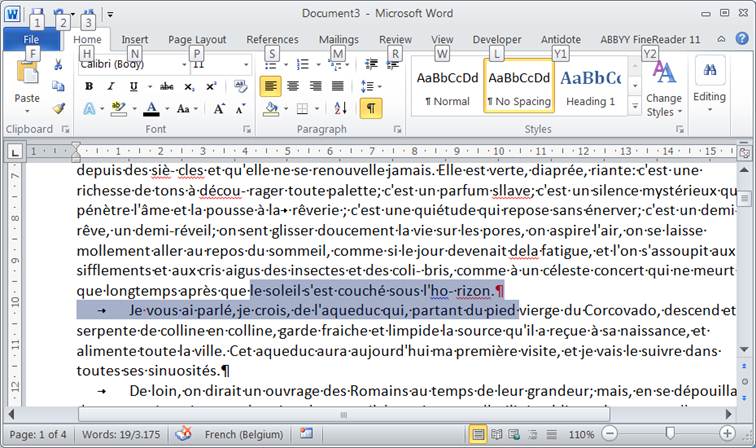
Il vous reste maintenant le plus long : relire le document word en vous reportant au PDF original pour ajuster le document Word.
Si vous avez des images, ‘pdftoimage.exe’, qui fait aussi partie de ‘xpdf’ est vraiment très bon.
ensuite, j’utilise gimp (autre freeware) pour le traitement et l’incorporation de l’image dans le document word.
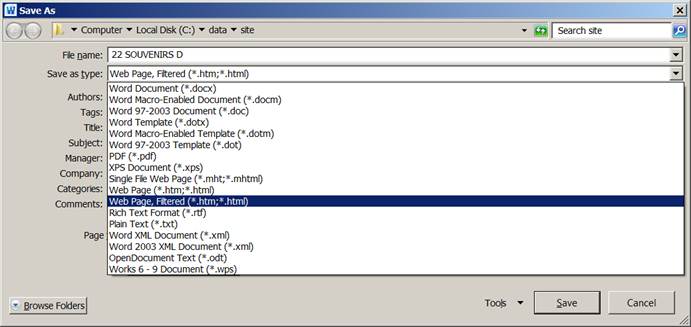
Bien maintenant que la correction est finie, je sauve mon document word comme fichier ‘html Web filtered’ :
Il me
reste à importer cela dans calibre et lui demander de convertir en
ePup.
Si
vous ne connaissez pas encore calibre, sachez que c’est un
freeware et qu’il
fait autorité dans le monde de l’ebook.
On trouvera calibre ici :
Pour allez plus loin, je vous recommande aussi ce tutorial:
(cet autre article sur le traitement des images avec XDPF et Gimp 2

Le premier exemple partait d'un texte relativement simple.
Mais votre texte peut contenir un certain nombre de contrainte supplémentaires.
Soit le texte suivant :
corvette vous renient. Mais, tenez, voilà votre double pirogue qui vous tend les bras ; prenez garde de la chavirer; relevez votre houppelande qui traîne. Bon- jour, Bordelais! Tiens, où donc est-il? Il m'a glissé dans les mains.
pare. La relâche sera amusante.
- tion, s'élança pour adresser quelques mots d'excuse à M. Rives, qui débordait, et fit faire à Marchais une faction de deux heures sur les barres de cacatois. Pe- tit dit alors entre ses dents : — Suffit, son affaire est faite.
nous nous amuserons quand tu seras descendu. |

| Search | Replace | Cocher 'expression régulirère' |
| ^p^p | ^P | |
| ^p | XXP | |
| XXP—<espace> | XXP— | |
| XXP—^t | XXP— | |
| .<espace>XXP | .XXP | |
| !<espace>XXP | !XXP | |
?<espace>XXP | ?XXP | |
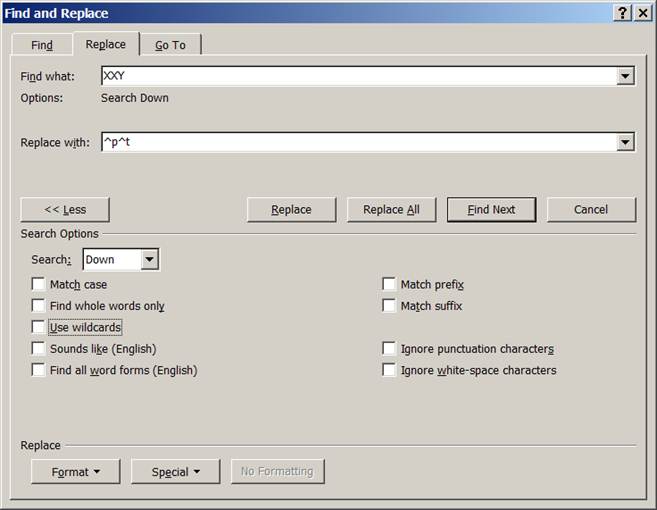
| ([\.\!\?])XXP([A-Z—]) | \1XXY\2 | Y |
| XXY | ^p^t | |
| XXP | ||
| —([A-Z]) | —<espace>\1 | Y |
